赵岩露1,2 王晶1,2沈奇威1,2
(1.北京邮电大学网络与交换技术国家重点实验室 北京100876)
(2.东信北邮信息技术有限公司 北京100191)
摘要:随着社会化网络的兴起,微博系统在日常生活中扮演着越来越重要的作用。信息过载问题的出现,为个性化推荐系统提供了新的挑战。为了对用户提供更优质的推荐,基于用户兴趣模型的推荐系统的效率显得尤为重要。本文在综合兴趣模型研究现状的基础上,结合微博数据集对微博用户的特征进行分析,建立微博用户兴趣模型,并提出基于微博用户兴趣模型的发现算法。实验结果表明,本文提出的算法能很好的发现微博用户的兴趣,提高推荐系统的质量。
关键字:微博 兴趣模型 特征分析 推荐系统 协同过滤
Feature Analysis Based Weibo User Interest Detection Algorithm
Zhao Yanlu1,2, Wang Jing1,2, Shen Qiwei1,2
(State Key Laboratory of Networking and Switching Technology, Beijing University of Posts
and Telecommunications, Beijing 100876, China)
(EB Information Technology Co. Ltd., Beijing 100191, China)
Abstract: With the rise of social networking, weibo systems play an increasingly important role in everyday life. A new challenge to personalized recommendation is provided when problem of system information overload appears. The efficiency of recommendation system which is based on user interest model is particularly important for the goal of better quality of the recommendation. Based on the research of user interest model, the feature of weibo user will be analyzed according to the weibo data collection, detection algorithm of weibo user interest model will be proposed. Experimental results indicate the algorithm we proposed performs better in detecting weibo user interest and enhances the quality of the recommendation system.
Key words: weibo; interest model; feature analysis; recommender system; collaborative filtering
1. 引言
个性化推荐是一种广泛使用的Web个性化服务应用程序,它根据用户的兴趣和特点,对信息资源进行收集、整理和分类,向用户提供和推荐符合其兴趣偏好或需求的信息[1]。而个性化推荐的本质是如何描述和发现用户的兴趣[2]。
社交网络服务作为社会化媒体的出现,已经在用户的日常生活中占据很大的地位。腾讯微博,作为中国最大的微博网站之一,拥有超过2亿注册用户,每天产生超过4000万条消息。由于社交网络中用户的入度和出度的分布也是满足长尾分布的[3],并且对于使用者来说用户比消息本身重要的多,因此如何给用户推荐其感兴趣的用户,并减少信息超载的风险就成了亟待解决的问题,也提供了寻求新的数据挖掘解决方案的机会[4]。
本文在腾讯微博的开放数据集基础上,分析用户的特征信息(包括用户的个人基本信息、用户的微博信息、用户的行为信息和用户的关注信息),建立用户兴趣模型,发掘用户的相关用户列表,采用协同过滤的方法为用户推荐其可能感兴趣的明星用户,达到个性化推荐的效果。
2. 兴趣模型研究现状综述
用户兴趣模型适用的场合很广泛,无论是电子商务、社交网络还是搜索引擎。
如何规划系统的动作, 也是构建用户模型过程中的一大难点[5][6]。
衡量一个用户兴趣模型好坏的主要因素是其表示用户兴趣的能力[7]。用户兴趣模型的计算方法主要采用协同过滤算法。学术界对协同过滤算法进行了深入研究,提出了很多方法,比如基于领域的方法、隐语义模型、基于图的随机游走算法等[3]。现有的协同过滤算法在计算推荐过程中将用户访问过的每个资源同等对待,这显然是不合理的。在微博数据中,要结合用户对每个用户的实际交互行为,考虑为用户间分配不同的权重。
在微博系统中,由于微博信息的不断更新增多,所以信息的数量级比用户的数量级大,考虑到计算时间和复杂度,就需要采用基于用户的协同过滤推荐算法[8]。
3. 微博数据集描述
微博数据集描述如表1所示。
本文认为一个微博数据集的特征应包括用户的个人信息,微博信息,社交关系信息和行为信息这四个维度。其中个人信息反映用户的基本社会属性,微博信息反映用户微博的的内容,社交关系信息反映用户的社交圈,行为信息反映用户的互动情况。这四个维度能很好的反映微博用户的兴趣,本文的兴趣模型都是围绕这些特征而进行分析计算。
4. 算法描述
4.1. 核心算法
将用户的特征划分为相互独立的三个模型计算与其可能相关的用户:
(1) 个人信息相关度模型:定义根据用户的个人信息计算与其相关的用户的方法为calcUserProfile。
(2) 微博信息相关度模型:定义根据用户的微博内容信息计算与其相关的用户的方法为calcUserKeyWord。
(3) 社交信息相关度模型:定义根据用户社交关系信息和行为信息计算与其相关的用户的方法为calcUserSNS。
采用这三个模型分别计算用户的相关用户列表,结合模型融合的技术和TOP-N算法得到最终的推荐明星列表。
核心算法思路如图1所示。
|
数据集名称
|
数据集意义
|
数据集格式
|
|
用户个人数据user_profile
|
用户的个人信息。
|
(UserId)\t(Year-of-birth)\t(Gender)\t(Number-of-tweet)\t(Tag-Ids)
Year-of-birth:用户注册的出生年份;Gender:用户性别;Number-of-tweet:用户已经发布的微博的数量;Tag-Ids:用户选择以表现其兴趣的标签。
|
|
用户关键词数据user_key_word
|
从每个用户的微博/转发/评论中提取出的关键字。
|
(UserId)\t(Keywords)
Keywords:从用户的微博、转发、评论中抽取的,可以在预测模型中,表示用户特征,权值越高表示该用户对该关键字兴趣越大。
|
|
用户社交关系数据user_sns
|
用户的关注历史
|
(Follower-userid)\t(Followee-userid)
|
|
用户行为数据user_action
|
最近一段时间内用户之间'at'(@)的统计数据
|
(UserId)\t(Action-Destination-UserId)\t(Number-of-at-action)\t(Number-of-retweet)\t(Number-of-comment)
Number-of-at-action:@次数;Number-of-retweet:转发次数;Number-of-comment:评论次数
|
表 1微博数据集
Table1 Weibo data collection
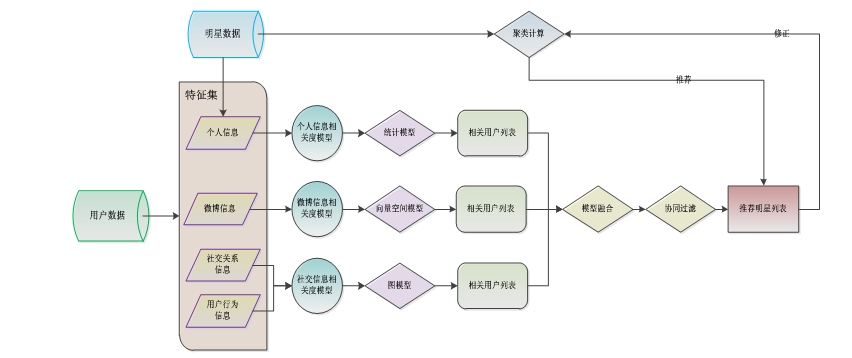
图 1核心算法图
Figure 1 Core algorithm chart
|
统计项
|
判断条件
|
权值
|
|
年龄
|
相差0-5岁
|
0.1
|
|
相差6-10岁
|
0.02
|
|
相差超过10岁
|
0.0
|
|
性别
|
相同
|
0.1
|
|
不同
|
0.0
|
|
微博数
|
小于50条
|
0.0
|
|
大于50条
|
0.1
|
|
用户标签
|
相似度
|
相同标签权值乘积的加权值
|
表2 个人信息相关度表
Table2 Personal information relevance table
4.1.1. 个人信息相关度模型
calcUserProfile采用统计的方法计算,计算方法如表2所示。系统中采用0.3作为阈值,与当前用户相关度权值超过0.3的用户按序组成与当前用户的相关用户列表。
4.1.2. 微博信息相关度模型
calcUserKeyWord采用向量空间模型计算。
当需要对未知用户和用户兴趣模型进行比较时,就通过计算未知用户的关键词权重向量  和用户兴趣度向量
和用户兴趣度向量 之间的余弦相似度公式(1)来度量, Sim(V,W)越大,说明两个向量的匹配程度越高。
之间的余弦相似度公式(1)来度量, Sim(V,W)越大,说明两个向量的匹配程度越高。

在微博信息相关度模型中,文本是用户,词组是用户的关键词信息。系统中采用0.05作为阈值,与当前用户相似度权值超过0.05的用户按序组成与当前用户的相关用户列表。
4.1.3. 社交信息相关度模型
calcUserSNS采用图的模型计算。
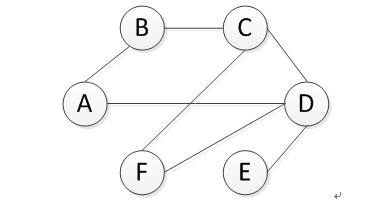
图 2用户关系图模型
Figure 2 User Relationship graph model
如图2所示,令G(V,E)表示用户与用户间关系的无向图,其中V是所有用户顶点的集合,E是用户与用户之间的边,代表用户之间的相关程度。
本文采用基于随机游走的PersonalRank算法来计算图中顶点之间的相关性。
假设要对用户A进行用户推荐,可以从用户A对应的节点 开始在图上进行随机游走,游走到任何一个节点时,首先按照概率α决定是继续游走,还是停止这次游走并从节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中用户的权重就是用户节点的访问概率。
开始在图上进行随机游走,游走到任何一个节点时,首先按照概率α决定是继续游走,还是停止这次游走并从节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中用户的权重就是用户节点的访问概率。
上面的描述可以用公式(2)表示:
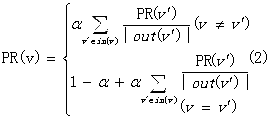
在社交信息相关度模型中,系统采用系数α为0.8。对收敛后的用户节点的访问概率进行排序,即得到与当前用户相关的用户列表。
4.1.4. 模型融合
单独采用以上的某个模型都不能很好的解决推荐问题,所以需要采用模型融合的技术,将各个模型的结果进行融合,从而得到最终的推荐结果。
在本文中,采用加权融合的方法,优先级为社交信息模型>微博信息模型>个人信息模型。为了避免过拟合的问题,利用最小二乘法[9],计算出三个模型的线性加权系数依次为0.8,0.5,0.3。将各个模型的预测结果值乘以线性加权系数并排序即得到最终的相关用户列表。
4.1.5. 产生推荐结果
对当前用户的相关用户列表,采用TOP-N算法进行明星用户推荐。Top-N 推荐是针对单个用户产生的,它对每个人是不一样的:通过对你的相关用户列表进行统计,选择累积出现权值最高的且不在你的关注列表中的N个明星用户作为推荐结果。
4.2. 冷启动问题
在推荐系统中,必须考虑系统冷启动的问题[10],也就是用户的行为数据不足的情况下系统推荐的问题。聚类算法作为无意识的自动发现算法,能很好的解决系统的冷启动问题。本文采用改进的K-means算法,聚合出系统中明星的类别,为用户推荐主流类别的用户。
5. 实验结果
5.1. 评测指标
主要依据信息检索的常用指标,召回率、正确率和F-Measure[11]。正确率(Precision)定义为系统的推荐列表中用户喜欢的产品和所有被推荐产品的比率。召回率(Recall)定义为推荐列表中用户喜欢的产品与系统中用户喜欢的所有产品的比率。
为了同时考察正确率和召回率,Pazzani 等把二者综合考虑提出了F指标[12]。F指标定义为:

其中,P为正确率,R为召回率。由于F指标把正确率和召回率统一到一个指标,因此得到了广泛的应用。
测试采用的方法为K重交叉验证法。该方法是最为普遍的计算推广误差的方法之一。
5.2. 结果分析
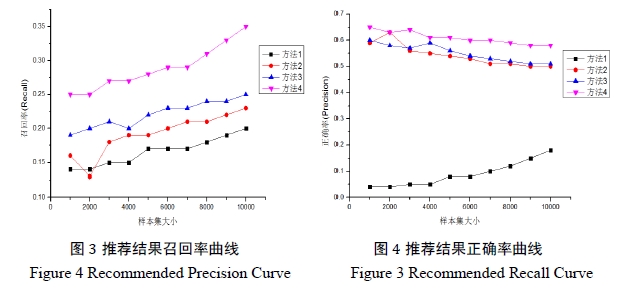
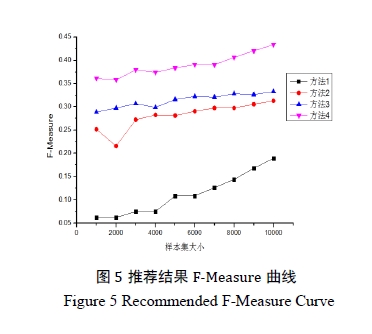
实验结果如图3-图5所示。
方法1:按照用户微博中提取出的关键字和明星的关键字直接进行相似度计算。由于本方法依赖用户和明星标签的规模,故随着样本用户集增大,召回率和正确率逐步增高,但是正确率仍旧在一个较低的范围之内。值得注意的是,其召回率在正常的范围内不断稳定增长。
方法2:采用分析提取用户好友列表的方法,将好友列表中用户关注的明星做统计计算。本方法受用户集增大而较大的影响,但是用户集规模到达一定地步之后,用户的关系网趋于稳定,影响幅度变得很小。同时,可以看出本方法的正确率始终保持在很高的规模,这样从侧面验证了微博中用户关注的重要意义。
方法3:采用本文提出的基于特征分析的兴趣发现方法。 兼顾了方法1和方法2的优点,结果显示其召回率不断提升,正确率也维持在一个满意的规模内。各项指标较前两种方法都有一定的提升。
方法4:采用聚类的方法解决冷启动问题。主要解决了召回率较低的问题,从系统内明星中进行聚类发掘,并根据用户反馈修正更新推荐结果,可以看到在保证正确率维持在原有规模的基础上,召回率较之前的三种方法有较大程度的提升。
总的来看,由3个图比较可见,改进后的算法(即方法4)能得到最大且稳定的召回率和正确率。
 搜索
搜索
 关注微信
关注微信



