孙乃利1,2 王玉龙1,2 沈奇威1,2
(1.北京邮电大学网络与交换技术国家重点实验室 北京100876)
(2.东信北邮信息技术有限公司 北京100191)
摘要: 基于对已有成果的借鉴,从用户影响力和活跃度两方面出发,主要针对微博中存在的“互关注”风气及“即逝意见领袖”问题,构建了用户领袖值评分指标体系,并提出了用户领袖值的量化定义,最后在获取的新浪微博真实数据集上进行了验证,确保了本文识别机制的有效性。
关键词:微博客,意见领袖,识别,AHP,指标权重
A Research on Opinion Leader Identification in Micro-blogging
Sun Naili, Wang Yulong, Shen Qiwei
(State Key Laboratory of Networking and Switching Technology, Beijing University of Posts
and Telecommunications, Beijing 100876, China)
(EBUPT Information Technology Co. Ltd., Beijing 100191, China)
Abstract: Based on the previous research, the rating index system for user leadership value, which mainly focuses on the problems such as “mutual-concern” and “namely-die opinion leader”, has been constructed from user influence and active degree two aspects. Then the quantitative definition of the leadership value has been put forward. At last the verification for the identification mechanism in this paper has been done on the real data set collected from Sina MicroBlog to ensure the effectiveness.
Keywords: Micro-blogging ;Opinion leader; Identification; AHP; Index weight
1 引言
微博客(简称微博),是web2.0时代兴起的一种互联网社交网络服务,它基于用户之间的关联关系,构筑了一个信息传播和分享的平台 [1],已经成为当今社会信息传播和交流的重要工具。据一项调查结果显示,Twitter上的2万名精英用户吸引了Twitter近50%用户的注意力,而这2万名精英仅占Twitter用户总量的0.05%,我们可以看到微博平台中存在一些重要的“信息输出用户”[2],这些重要的“信息输出用户”中是否存在意见领袖呢?周庆山在《微博中意见领袖甄别与内容特征的实证研究》一文[3]中给出了肯定的回答。
自2011 年始,对微博意见领袖的研究开始出现,总体而言,对微博意见领袖的研究尚处于起步阶段,尤其在采用科技手段进行量化研究方面尚未有太多进展。本文将在相关研究的基础上,通过新浪微博用户数据的实验分析,找出识别意见领袖的量化规则,以便科学快速地发掘微博客意见领袖。
2 实验数据集
为了采集实验所需数据,本文选取了国内发展最迅速的微博服务“新浪微博”作为数据来源。利用微博爬虫,于2012 年5 月份共计采集了50000位微博用户的信息。初步的统计信息如表1所示:
表 1 数据集初步统计结果
|
用户属性
|
最大值
|
最小值
|
平均值
|
|
粉丝数
|
21527019
|
0
|
1206
|
|
互关注数
|
1897
|
0
|
168.3
|
|
微博数
|
54281
|
0
|
1013.2
|
|
单条微博转发数
|
51260
|
0
|
1000.5
|
|
单条微博评论数
|
36776
|
0
|
896.4
|
|
是否认证
|
1
|
0
|
0.021
|
|
回复发布数
|
823
|
0
|
107.3
|
|
活跃天数
|
31
|
0
|
14.1
|
注:从统计数据可以看出,单条微博的转发数和评论数均值都比较高,这是因为微博中多数的内容都来自那些“信息输出用户”,而来自这些用户的内容都会有比较高的关注度,因此单条微博的转发数与评论数均值较高。
3 微博意见领袖识别
3.1 领袖值评分指标体系
根据意见领袖的定义,微博平台中的意见领袖应该有一定影响力和活跃度。下面将从这两个方面构建用户领袖值评分指标体系,用户领袖值越高说明用户是意见领袖的概率越大。
3.1.1 用户影响力
本文使用用户影响力这个二级指标来衡量一个用户对其他用户产生影响的可能性。通过分析从新浪微博中获取的数据集,以下属性可以作为用户影响力的考虑因素:
(1) 粉丝数
足够的粉丝数是用户影响力的必要条件,所谓“有之不必然,无之必不然”,粉丝数是影响用户影响力的一个重要因素。
(2) 互关注数
鉴于目前微博上盛行的“互粉”风气[2],即A用户先行单方关注B用户,B用户出于行为惯式或礼貌,也对A用户加以关注。这样产生的粉丝量并不真正体现用户的影响力,因此对于这部分粉丝量应该予以剔除,以修正粉丝数在用户影响力上的贡献。
(3) 是否认证
通过对微博中认证用户的观察不难发现,认证用户往往都在现实社会中有一定知名度,其现实社会影响力辐射到了微博领域,往往能够吸引更多人的关注。因此,就用户的影响力而言,是否认证也是一个重要表征。
(4) 微博转发数和评论数
就单条微博来讲,通过转发行为该微博会以一种级联方式传播给更多用户,一条微博的转发次数越多,产生的影响越大;得到的评论越多,说明该微博引起其他用户的关注越多,影响范围也越广。就用户来讲,用户所有微博得到的总评论数、总转发数越大,说明用户的影响力越大。
有观点提出,粉丝数越大,微博的可见度就越大,被转发和评论的概率也就越大,因此转发数和评论数与粉丝数有一定的趋同性,但是“即逝意见领袖”[3]现象的出现否定了这一论断。所谓“即逝意见领袖”是指在某一热点事件爆发的过程中瞬间受到百万点击量,而事件结束之后淡出公众视野的人群,如郭美美事件、温州动车事件的当事者等都是在瞬间就激增了大量的粉丝,其粉丝量也在十万甚至百万级别,但是与真正的意见领袖相比,他们的转发量和评论量都是微不足道的。因此,微博转发数和评论数与粉丝数成趋同性的结论是不成立的,应当作为用户影响力的重要考量因子。
3.1.2 用户活跃度
意见领袖需要考量的第二个二级指标是用户的活跃度,在微博平台中,这个指标主要体现在以下几方面:
(1) 原创微博数
作为意见领袖,应该有自己的认识,原创微博数越多说明用户表达的自我思想越充分。
(2) 回复发布数
回复发布数是指用户对其他发出的回复量,通过回复行为,可以与其他用户进行交流,发出的回复数越多,说明用户间的交流越多,用户本身的活跃度也越高。
(3) 活跃天数
一个活跃用户不仅应该在事件爆发时活跃于该领域,应该给予持续的关注,活跃天数越多说明用户在该领域的关注越持久,这一因素也有助于对“即逝意见领袖”的过滤。
3.1.3 指标层次结构
通过3.1.1节和3.1.2节的分析,我们得出领袖值评分指标体系如图1:
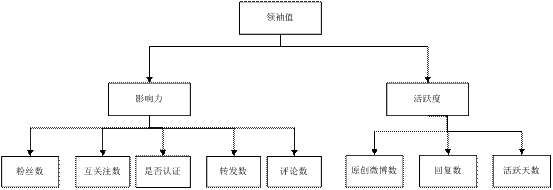
图 1 领袖值评分指标体系
3.2 基于AHP的指标权重确定
由于不同指标的重要性有所不同,有必要使用指标权重反应这种差异,本文使用层次分析法(AHP)计算各指标的权重。
3.2.1 AHP层次分析法介绍
层次分析法(Analytic Hierarchy Process,简称AHP)[4]是对一些较为复杂、较为模糊的问题作出多准则决策的简易方法,它特别适用于那些难于完全定量分析的问题。
层次分析法解决问题,大体分为以下四步:将问题分解,建立层次结构;构造两两比较判断矩阵;由判断矩阵计算比较元素的相对权重;计算各层元素的组合权重。
3.2.2 各指标权重的计算过程
首先使用标度法,分层对指标进行两两比较,得到各层次量化的判断矩阵。矩阵中,第i行第j列元素所表达的含义[5]如下:
1) 1 i因素与j因素同等重要
2) 3 i因素比j因素略重要
3) 5 i因素比j因素较重要
4) 7 i因素比j因素非常重要
5) 9 i因素比j因素绝对重要
6) 2,4,6,8 以上判断之间的中间状态对应的标度值
在判断矩阵中,aij = 1/aji。
然后使用AHP法计算出各层次指标单排序的结果并进行一致性检验[6],一致性检验是为了检验各元素重要度之间的协调性,避免A比B重要,B比C重要,而C又比A重要这样的矛盾情况出现。
最后利用上层元素的组合权重为权数,计算本层各元素的加权和,所得结果即为该层元素的组合权重,进行层次总排序。
经计算得出的各指标的组合权重为:
W粉丝数=0.875*0.2978=0.260575 W互关注数=0.875*0.2978=0.260575
W认证=0.875*0.0888=0.0777 W转发数=0.875*0.1578=0.138075
W评论数=0.875*0.1578=0.138075 W原创微博数=0.125*0.6=0.075
W回复数=0.125*0.2=0.025 W活跃天数=0.125*0.2=0.025
3.3 领袖值的量化定义
通过对领袖值评分指标权重的计算,定义公式(1)对用户领袖值进行量化:
Leadship = 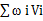 (1)
(1)
式中ωi代表指标i的权重,Vi代表指标i的度量值。
由于各指标是不可公度的, 为了便于比较和评价,本文将各指标数据进行归一化预处理。
需要指出的是,互关注数是一个负向因子,该指标使用式(2)来进行数据的预处理:
V = 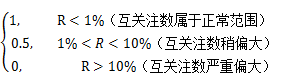 (2)
(2)
式中R= 。
。
而粉丝数,不同用户间差别巨大,如姚晨有2000多万粉丝,蔡康永有4万多粉丝,普通用户可能就只有几百粉丝,因此使用式(3)进行处理,,这样能将较大数量级的差别调整到一个合适的范围:
V =  (3)
(3)
其余指标,使用式(4)把数据变换到[ 0, 1] 区间:
V = 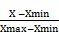 (4)
(4)
3.4 实验效果
本文在真实的数据上对提出的微博意见领袖识别体系进行了验证,实验数据集在上文已说明。通过本文的识别机制,得到如表2所示的结果:
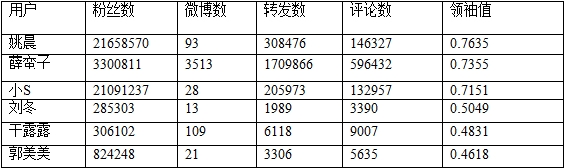
表中的结果表明,本文的识别机制可以有效的识别出接近于真实的意见领袖,如姚晨、薛蛮子等,并对刘冬、干露露、郭美美等“即逝意见领袖”进行了一定程度的过滤。

 搜索
搜索
 关注微信
关注微信



